
PAPER
- Dongjoo Kim and Minsik Lee, “Interpreting pretext tasks for active learning: a reinforcement learning approach,” Scientific Reports, vol. 14, pp. 25774, Oct. 2024. [paper]
ABSTRACT
As the amount of labeled data increases, the performance of deep neural networks tends to improve. However, annotating a large volume of data can be expensive. Active learning addresses this challenge by selectively annotating unlabeled data. There have been recent attempts to incorporate self-supervised learning into active learning, but there are issues in utilizing the results of self-supervised learning, i.e., it is uncertain how these should be interpreted in the context of active learning. To address this issue, we propose a multi-armed bandit approach to handle the information provided by self-supervised learning in active learning. Furthermore, we devise a data sampling process so that reinforcement learning can be effectively performed. We evaluate the proposed method on various image classification benchmarks, including CIFAR-10, CIFAR-100, Caltech-101, SVHN, and ImageNet, where the proposed method significantly improves previous approaches.
OVERALL FRAMEWORK
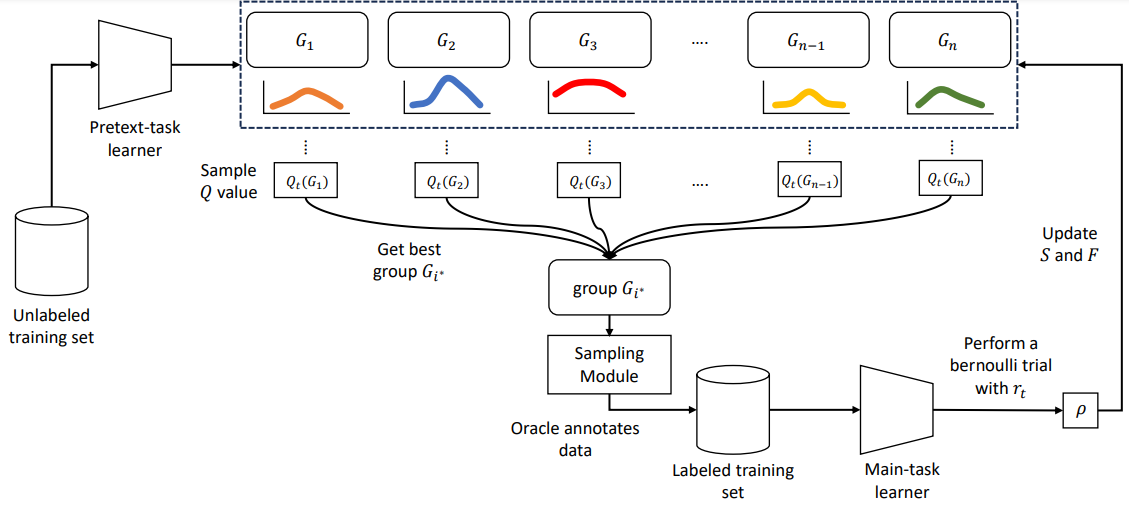
- The overall framework of the proposed method. Unlabeled training data are sorted based on pretext-task losses and split into groups. The optimal group is selected based on the cumulative rewards, on which the main-task learner is trained.